CEFR-Cymraeg: A Dataset and Baseline Models for Language Proficiency Assessment in Welsh
May 11, 2026·,, ·
0 min read
·
0 min read
Eeshan Waqar
Jonathan Davies
Dawn Knight
Fernando Alva-Manchego
Abstract
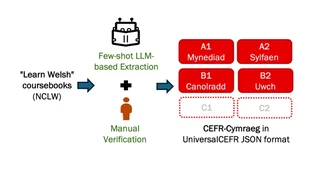
Automatic language proficiency assessment is a key task in computer-assisted language learning, yet Welsh remains severely under-resourced in this area. We present CEFR-Cymraeg, the first dataset annotated with Common European Framework of Reference (CEFR) proficiency levels for Welsh, sourced from coursebooks and validated by language instructors. The dataset spans levels A1 to B2 across 2,658 annotated entries. We establish baseline models and demonstrate that fine-tuned multilingual pre-trained language models achieve an F1-score of 0.83, effectively capturing language competency distinctions. Our dataset and models provide a foundation for developing Welsh-language learning tools and educational resources.
Type
Publication
LREC 2026
