Generative Language Models for Paragraph-Level Question Generation
December 9, 2022· ,·
0 min read
,·
0 min read
Asahi Ushio
Fernando Alva-Manchego
Jose Camacho-Collados
Abstract
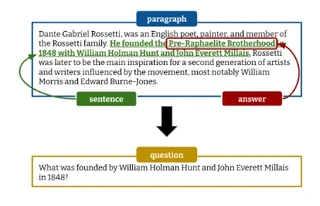
Powerful generative models have led to recent progress in question generation (QG). However, it is difficult to measure advances in QG research since there are no standardized resources that allow a uniform comparison among approaches. In this paper, we introduce QG-Bench, a multilingual and multidomain benchmark for QG that unifies existing question answering datasets by converting them to a standard QG setting. It includes general-purpose datasets such as SQuAD for English, datasets from ten domains and two styles, as well as datasets in eight different languages. Using QG-Bench as a reference, we perform an extensive analysis of the capabilities of language models for the task. First, we propose robust QG baselines based on fine-tuning generative language models. Then, we complement automatic evaluation based on standard metrics with an extensive manual evaluation, which in turn sheds light on the difficulty of evaluating QG models. Finally, we analyse both the domain adaptability of these models as well as the effectiveness of multilingual models in languages other than English.QG-Bench is released along with the fine-tuned models presented in the paper (https://github.com/asahi417/lm-question-generation), which are also available as a demo (https://autoqg.net/).
Type
Publication
EMNLP 2022
