UniversalCEFR: Enabling Open Multilingual Research on Language Proficiency Assessment
Nov 4, 2025·,,,,,,,,,,,,,,,, ,·
0 min read
,·
0 min read
Joseph Marvin Imperial
Abdullah Barayan
Regina Stodden
Rodrigo Wilkens
Ricardo Munoz Sanchez
Lingyun Gao
Melissa Torgbi
Dawn Knight
Gail Forey
Reka R. Jablonkai
Ekaterina Kochmar
Robert Reynolds
Eugenio Ribeiro
Horacio Saggion
Elena Volodina
Sowmya Vajjala
Thomas Francois
Fernando Alva-Manchego
Harish Tayyar Madabushi
Abstract
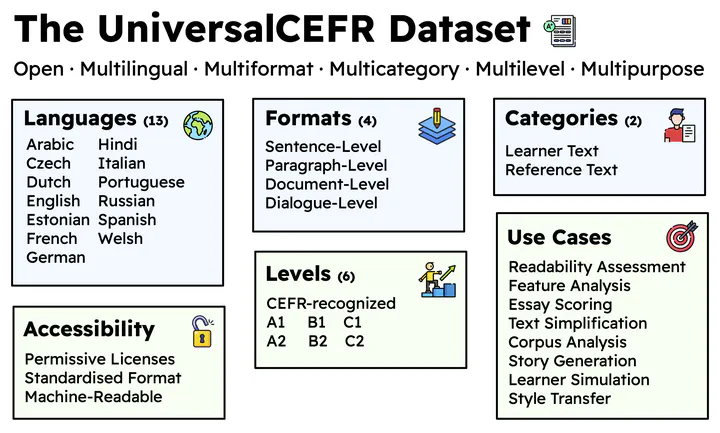
We introduce UniversalCEFR, a large-scale multilingual multidimensional dataset of texts annotated according to the CEFR (Common European Framework of Reference) scale in 13 languages. To enable open research in both automated readability and language proficiency assessment, UniversalCEFR comprises 505,807 CEFR-labeled texts curated from educational and learner-oriented resources, standardized into a unified data format to support consistent processing, analysis, and modeling across tasks and languages. To demonstrate its utility, we conduct benchmark experiments using three modelling paradigms: a) linguistic feature-based classification, b) fine-tuning pre-trained LLMs, and c) descriptor-based prompting of instruction-tuned LLMs. Our results further support using linguistic features and fine-tuning pretrained models in multilingual CEFR level assessment. Overall, UniversalCEFR aims to establish best practices in data distribution in language proficiency research by standardising dataset formats and promoting their accessibility to the global research community.
Type
Publication
EMNLP 2025