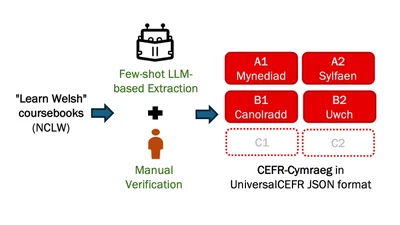
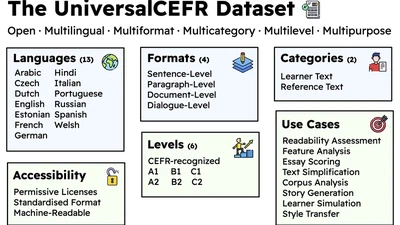
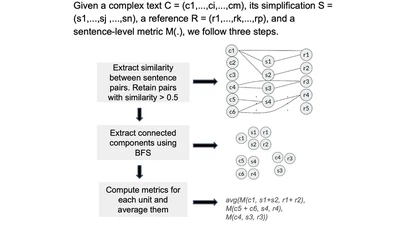
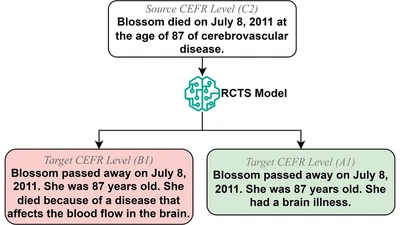
I am an NLP researcher and Lecturer (~Assistant Professor) at the
School of Computer Science and Informatics at
Cardiff University, and a member of the
Cardiff NLP group. My work focuses on text adaptation and readability: building systems that make language more accessible to diverse audiences, across multiple languages, and in real-world settings such as education, healthcare, and social care. Throughout, I prioritise human-centred evaluation and close collaboration with the practitioners and communities we aim to serve.